
Как запустить DeepSeek локально и использовать её для поиска по документации? Разбираем ключевые особенности модели, её преимущества перед ChatGPT, влияние на рынок и применение технологии RAG.
0157 открытий450 показов
Последние две недели интернет-общественность активно обсуждает DeepSeek — новую генеративную модель, которая вызвала большой интерес благодаря своей эффективности. Главный сюрприз: при качестве ответов, сравнимом с ChatGPT, её обучение обошлось значительно дешевле. Это уже повлияло на рынок: акции Nvidia потеряли около 20% стоимости всего за один день.
DeepSeek доступна бесплатно как через веб-интерфейс, так и через мобильное приложение. Однако сегодня мы рассмотрим не такой очевидный, но не менее важный аспект — локальный запуск модели.
Разберём это на примере небольшого проекта. Представьте, что у вас есть массив документации, и вам необходимо эффективно искать информацию или проводить анализ данных. Один из подходов, который можно применить, — технология RAG (Retrieval-Augmented Generation), которая сочетает поиск по тексту с генерацией ответов на основе релевантных данных. Давайте разберём, как DeepSeek можно адаптировать под эту задачу.
Что такое RAG?
Retrieval-Augmented Generation (RAG) – передовая техника ИИ, разработанная для повышения точности и надежности языковых моделей путем интеграции поиска внешней информации в процесс генерации ответа. В отличие от традиционных генеративных моделей, которые полагаются исключительно на обученные знания, RAG осуществляет динамический поиск релевантной информации перед генерацией ответа, уменьшая количество галлюцинаций и повышая точность фактов.
Определяем год рождения по знанию Рунета 2000-хtproger.ru
Процесс работы RAG состоит из трех ключевых этапов. Во-первых, он извлекает соответствующие документы или данные из базы знаний, которая может включать структурированные БД, векторные хранилища или даже API в режиме реального времени. Затем полученная информация объединяется с внутренними знаниями модели (это гарантирует, что ответы будут основаны на актуальных и надежных источниках). Наконец, модель генерирует обоснованный ответ, используя как свои обученные языковые возможности, так и новые полученные данные.
Такой подход дает значительные преимущества. Основывая ответы на внешних источниках, RAG минимизирует неточности и обеспечивает актуальность информации, что делает его особенно полезным в финансах, здравоохранении и праве. Он широко применяется в чат-ботах, системах ИИ с расширенным поиском, корпоративном поиске знаний и управляемыми ИИ научными ассистентами, где точность и достоверность фактов имеют решающее значение.
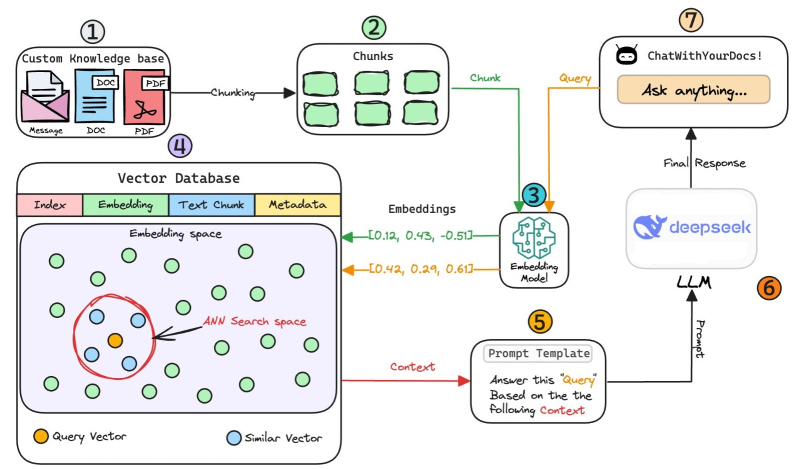
Как будет выглядеть архитектура решения?
База знаний — коллекция релевантной и актуальной информации, которая служит основой для RAG. В нашем случае это документы, хранящиеся в каталоге.
Перед тем, как начать реализовывать данную архитектуру, необходимо установить следующие библиотеки (тестировалось на Python 3.11):
llama-index transformers torch sentence-transformers llama-index-llms-ollama
Вот как вы можете загрузить ваши документы в LlamaIndex в виде объектов:
from llama_index.core import SimpleDirectoryReader loader = SimpleDirectoryReader( input_dir=input_dir_path, required_exts=[".pdf"], recursive=True ) docs = loader.load_data()
Векторные хранилища принимают список объектов Node и строят из них индекс.
VectorStoreIndex в RAG
В системе Retrieval-Augmented Generation (RAG) индекс VectorStoreIndex используется для хранения и извлечения векторных вкраплений документов. Это позволяет системе находить релевантную информацию на основе семантического сходства, а не точного совпадения ключевых слов.
Процесс начинается с встраивания документов. Текстовые данные преобразуются в векторные вкрапления с помощью модели. Эти вкрапления представляют смысл текста в числовой форме, что облегчает сравнение и поиск похожего контента. После создания вкрапления хранятся в векторной базе данных — FAISS, Pinecone, Weaviate, Qdrant или Chroma.
Гайд: как настроить API-распознавание документов за 30 минутtproger.ru
Пользователь отправляет запрос, который также преобразуется во вкрапление с помощью той же модели. Затем система ищет похожие вкрапления, сравнивая запрос с сохраненными векторами с помощью метрик сходства — косинусоидального сходства или евклидово расстояния. Наиболее релевантные документы извлекаются на основе их оценок сходства.
Полученные документы передаются в качестве контекста в большую языковую модель (LLM), которая использует их для создания ответа. Этот процесс гарантирует, что LLM имеет доступ к релевантной информации, повышая точность и уменьшая количество галлюцинаций.
Использование VectorStoreIndex улучшает системы RAG, обеспечивая семантический поиск, улучшая масштабируемость и поддерживая поиск в реальном времени. Это гарантирует, что ответы будут контекстуально точными и основанными на наиболее релевантной доступной информации.
Построить векторный индекс очень просто:
from llama_index.core import VectorStoreIndex index = VectorStoreIndex.from_documents(docs) # Save the index to a file index.storage_context.persist(persist_dir="./index")
Дальше остается скачать и запустить модель deepseek-R1 с помощью ollama. Для этого необходимо установить ollama https://ollama.com/download.

deepseek-r1ollama.com
После того, как вы запустите у себя эту модель командой
ollama run deepseek-r1:1.5b
достаточно выполнить следующий код, чтобы RAG начал работать
from llama_index.core import StorageContext, load_index_from_storage from llama_index.core import Settings, PromptTemplate from llama_index.llms.ollama import Ollama # rebuild storage context storage_context = StorageContext.from_defaults(persist_dir="./index") # load index index = load_index_from_storage(storage_context) # Creating a prompt template qa_prompt_tmpl_str = ( "Context information is below. n" "__n" "{context_str} n" "__in" "Given the context information above I want you n" "to think step by step to answer the query in a crisp n" " manner, incase case you don't know the answer say n" "'I don't know!'. n" "Query: {query_str}n" "Answer: ") qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str) # Setting up a query engine llm = Ollama(model="deepseek-r1:1.5b", request_timeout=360.0) # Setup a query engine on the index previously created Settings.llm = llm # specifying the llm to be used query_engine = index.as_query_engine( similarity_top_k=10 ) query_engine.update_prompts({"response_synthesizer:text_qa_template": qa_prompt_tmpl}) response = query_engine.query('What is the ACID?') print(response)
Теперь можно встроить данное решение в десктопный клиент, создав пользовательский интерфейс с помощью Streamlit, чтобы обеспечить взаимодействие пользователя через чат с приложением RAG. Либо можно сделать телеграм-бот, тогда создать интерфейс будет ещё проще.