
Pandas, Polars или PySpark — что выбрать для работы с данными? Вместе с Никитой Егоровым, ведущим аналитиком в МТС Диджитал, разбираем отличия, плюсы и минусы каждого инструмента.
139 открытий200 показов
В мире аналитики данных выбор правильного инструмента — ключ к эффективной и быстрой работе. Pandas, Polars и PySpark помогают обрабатывать большие объемы числовой информации, но каждый из них предназначен для разных сценариев. Если выбрать неподходящий инструмент, можно столкнуться с проблемами: скрипты будут работать медленно, потреблять слишком много памяти или вовсе падать с ошибками.
Вместе с Никитой Егоровым, ведущим аналитиком в МТС Диджитал и автором тг-канала Дата аналитикс, разберем, чем отличаются Pandas, Polars и PySpark, какие у них сильные и слабые стороны, и какой инструмент выбрать в зависимости от задач.

Никита Егоров
Ведущий аналитик в МТС Диджитал, автор тг-канала Дата аналитикс
P.s. Если не видели первую часть из нашей дата-серии, самое время исправить. Там рассказываем про партиционирование.
Как понять партиционирование: DWH для гуманитариевtproger.ru
Почему важно выбрать правильный инструмент для работы с данными?
От выбора инструмента зависит не только удобство работы, но и производительность системы. Вот краткое сравнение трех решений:
- Pandas — идеален для небольших данных (до 1-3 ГБ). Простой, удобный, но начинает «задыхаться» на больших объемах.
- Polars — работает в 1.5–10 раз быстрее Pandas за счет многопоточности и использования Rust. Отлично справляется с 7-25 ГБ, но требует больше памяти.
- PySpark — создан для работы с огромными объемами данных (30+ ГБ). Позволяет распределять вычисления по кластерам, но сложнее в настройке.
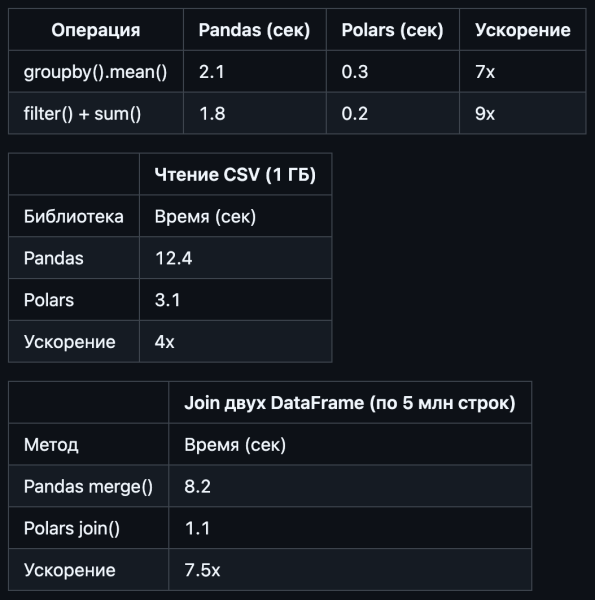
Тесты на CPU Intel i7-11800Н, 32 ГБ ОЗУ, данные синтетические
Как понять, что ваш инструмент больше не справляется?
Если ваш скрипт выполняется дольше, чем вы пьете кофе, или падает с ошибкой MemoryError, пора задуматься о переходе на Polars или PySpark.
Pandas: золотой стандарт для аналитиков
Почему Pandas остается первым выбором?
Pandas — это удобство, простота и огромное количество готовых решений. Он идеально подходит для:
- Разведочного анализа данных (EDA) — позволяет понять структуру данных, выявить пропуски, выбросы и тренды.
- Обработки файлов CSV/Excel до 1-3 ГБ.
- Интеграции с библиотеками визуализации (Matplotlib, Seaborn).
Ограничения Pandas
- Проблемы с памятью. Например, датафрейм весом ~20 ГБ уже вызовет MemoryError.
- Скорость обработки. Данные объемом 1 ГБ при 32 ГБ ОЗУ и процессоре Intel Core i7 11800H обрабатываются за 12.4 секунды на синтетических данных.
- Нагрузка на систему. При обработке 2-5 ГБ ваш ноутбук может начать перегреваться и замедлять работу.
Polars: быстрая и оптимизированная альтернатива Pandas
Почему Polars быстрее?
Polars написан на Rust, а это компилируемый язык без накладных расходов, который выполняется в 10-100 раз быстрее, чем интерпретируемый Python. Полностью поддерживает многопоточность, что делает его значительно быстрее Pandas.
Когда использовать Polars?
- При обработке данных 5-30 ГБ (например, логи, транзакции).
- Когда Pandas уже не справляется, но PySpark кажется избыточным.
- Для SQL-подобных операций (
group_by,join).
Недостатки Polars
- Меньше документации и примеров — интеграция с
SeabornиMatplotlibотсутствует. - Некоторые методы работают иначе. Например, фильтрация в Pandas и Polars:
# Pandas df[df['age'] > 18] # Через булеву маску # Polars df.filter(pl.col('age') > 18) # Явный метод filter()
Polars — это как Pandas, но после курса энергетиков — синтаксис похож, но под капотом всё оптимизировано и разогнано
PySpark: для работы с огромными объемами данных
Когда использовать PySpark?
- Если объем данных превышает 30 ГБ;
- Если нужны распределенные вычисления (кластеры, облака);
- Для потоковой обработки данных (например, Kafka + Spark).
Какие сложности у PySpark?
- Требует JVM (Java), правильных версий Spark/Hadoop, совместимости Python-библиотек.
- Нужно настраивать spark-defaults.conf, выделять память (spark.driver.memory, spark.executor.memory). Это особенно критично для больших данных.
- Частые проблемы с путями, отсутствием классов Java (ClassNotFoundException), конфликтами версий.
- Локальный режим ≠ продакшен. Локальный Spark (например, local[*]) не всегда корректно эмулирует кластер, что маскирует проблемы масштабирования.
Нужно ли аналитикам учить PySpark, если они не работают с Big Data? Если ваши данные умещаются в Excel — нет. Но если планируете работать с большими объемами или в BigTech, лучше изучить хотя бы основы.
Какой инструмент выбрать аналитику?
Исходя из сводной таблички, делаем вывод, какой минимальный набор инструментов должен знать аналитик в 2025 году:

- Pandas — обязательно.
- Polars — желательно.
- PySpark — если работаете с большими данными.
Таким образом, выбирайте инструмент под задачу, а не под моду:
- Pandas — для разведочного анализа и небольших данных.
- Polars — когда нужны скорость и многопоточность.
- PySpark — для распределенных вычислений и огромных объемов данных.
Понимание этих инструментов поможет работать эффективнее и выбирать правильные решения для каждой задачи.