
Data Science продолжает набирать обороты, а вместе с ней — и языки программирования. Ниже — большая подборка библиотек и фреймворков Python для работы с данными, которые будут актуальны в наступающем году (и не только).
137 открытий256 показов
Python в сфере Data Science остается топ-1 языком — это основная технология для для обработки данных, машинного обучения и разработки аналитических моделей. Например, в машинном обучении Питон используют 69% разработчиков. И в 2025 году году этот тренд будет только расти благодаря как развитию существующих инструментов, так и созданию новых.
Python стал производительнее и «многопоточнее»: GIL теперь опционаленtproger.ru
Разработчики выбирают Python для аналитики данных и машинного обучения из-за его гибкости, универсальности, низкого порога входа и силы комьюнити. Он позволяет интегрироваться с практически любой технологией, а также поддерживает мощные библиотеки, такие как Pandas, NumPy и Scikit-Learn. А еще язык постоянно развивается — не так давно разработчики выкатили новую версию 3.13, в которой сильно улучшилась производительность. Ниже рассказываем о топовых фреймворках и библиотеках, которые будут популярны в 2025 году.
Библиотеки для сложных вычислений

NumPy и SciPy
NumPy стала основой для большинства других библиотек, включая TensorFlow и PyTorch. Он используется для работы с массивами и числовыми данными. В машинном обучении почти каждый проект основан на эффективных математических функциях NumPy и точных операциях с массивами. И в плане векторов и многопоточности эта библиотека незаменима — на ней все держится.
Например, NVIDIA разрабатывает CUDA — платформу параллельных вычислений и модель программирования для работы на графических процессорах NVIDIA. CUDA Array Interface стандартизирует формат передачи массивов GPU между библиотеками без копирования данных. Так, CuPy реализует массивы NumPy на GPU NVIDIA с использованием CUDA, а Numba компилирует Python-код для GPU с прямой поддержкой массивов NumPy. Apache MXNet использует NDArray — аналог NumPy для GPU, ускоряющий работу моделей глубокого обучения. Это к слову о том, что NumPy уже стала стандартом.
Поверх NumPy можно использовать SciPy — она расширяет способности базовой модели для статистики и моделирования.
Pandas
Pandas — еще один базовый инструмент для работы с данными в Python, который остается в топе благодаря производительности (Панды отлично справляются с огромным количеством данных). Она, кстати, тоже используется поверх NumPy.
Возможно, в будущем мы увидим улучшение поддержки многопоточности и оптимизацию для работы с большими наборами данных — это сделает библиотеку ещё актуальнее.
Панды используют для подготовки данных во многих проектах — от финансового анализа до биоинформатики. Например, в здравоохранении с помощью Pandas анализируют электронные медицинские записи и прогнозируют эпидемии.
Dask
Dask используется для распределённых вычислений и параллельной обработки больших массивов данных. Он является топовым дополнением к Pandas в случаях, когда объемы данных превышают возможности оперативной памяти. В будущем всё больше компаний будут применять связку Pandas + Dask, чтобы масштабировать свои аналитические системы.
JAX
Новая селебрити в вычислениях от Google! JAX активно набирает популярность за счет своей способности ускорять численные расчеты и различать собственные функции Python и NumPy. Ожидается, что к 2025 году JAX будет активно применяться для статистического моделирования и разработки новых алгоритмов.
Топовые фреймворки для Machine и Deep Learning

TensorFlow — базовая база
TensorFlow от Google остается основным инструментом в машинном обучении благодаря своей мощной экосистеме, включающей компоненты для обучения, развертывания и мониторинга моделей. Сейчас он выделяется улучшенной интеграцией с облачными платформами (особенно с Google Cloud) и поддержкой edge-устройств — это упрощает развертывание моделей в разных средах.
Так, TensorFlow Lite позволяет запускать модели на мобильных устройствах, IoT-устройствах и микроконтроллерах — инструмент используют в приложениях для распознавания речи и обработки изображений в реальном времени, в том числе и на смартфонах. А в TensorFlow Extended (TFX) есть фичи для построения масштабируемых пайплайнов, таких как автоматическая настройка моделей (TensorFlow Model Analysis) и эффективное развертывание (TensorFlow Serving). Это особенно полезно для продакшн-сред.
PyTorch
PyTorch стал любимчиком в среде разработчиков из-за удобства динамических вычислительных графов и pythonic-подхода, что упрощает отладку и разработку. PyTorch известен тем, что предоставляет две из самых высокоуровневых функций — тензорные вычисления с мощным графическим ускорением и поддержку построения глубоких нейронных сетей на ленточной системе autograd.
Keras
Сейчас Keras максимально интегрирован с TensorFlow, поэтому порог входа в машинное и глубокое обучение становится все ниже. Его высокоуровневый API позволяет разработчикам создавать прототипы сложных нейронных сетей с минимальным количеством кода, сохраняя при этом возможность выполнять операции более низкого уровня.
Scikit-learn
Scikit-learn сохраняет статус универсального инструмента для классического машинного обучения. Простота использования, стабильный API и широкая документация делают его максимально подходящим для задач от классификации до сложных пайплайнов, с акцентом на интеграцию с фреймворками глубокого обучения. В последних обновлениях улучшилась поддержка многопоточности и ускорений на основе Cython, а значит, работа с большим наборами данных идет быстрее.
FastAI
Фреймворк основан на PyTorch и продолжает демократизировать глубокое обучение. Действительно инновационный трендовый инструмент, особенно в области компьютерного зрения и NLP-задач.
PyCharet
Эта low-code библиотека превратилась в большое комплексное решение для автоматизации задач AutoML. Подходит для тестирования гипотез или базовых моделей, которые можно улучшать по мере необходимости, а еще крута в прототипировании.
Ray
Это унифицированный фреймворк для распределенных вычислений. То, что нужно в машинном обучении.
Библиотеки для визуализации данных
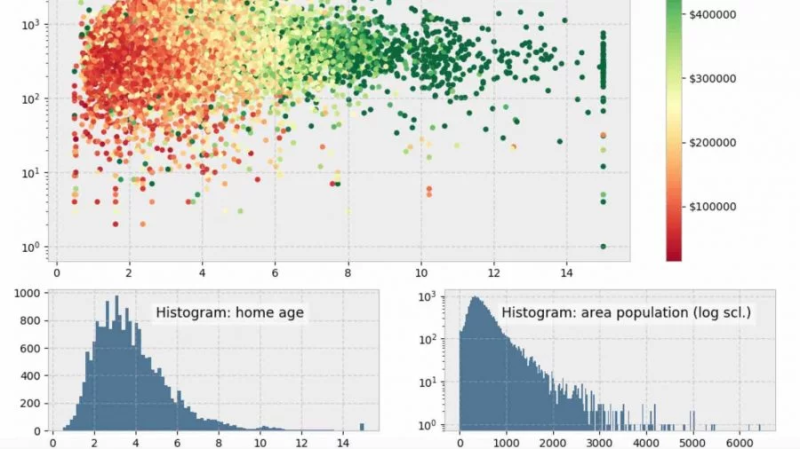
Визуализация с помощью Matplotlib
Matplotlib
Основная библиотека для создания статических графиков. Отлично подходит для базовой визуализации, такой как линейные графики, столбчатые диаграммы, гистограммы и так далее.
Seaborn
Построена поверх Matplotlib и предлагает более стильные и готовые к использованию графики. Удобна для работы с табличными данными (например, из pandas DataFrame).
Подходит для визуализации распределений, тепловых карт, корреляций.
Plotly
Интерактивная библиотека, поддерживающая 2D и 3D-графики. Удобна для создания сложных визуализаций, которые можно использовать в веб-приложениях. Поддерживает интеграцию с Jupyter Notebook.
Bokeh
Еще одна интерактивная библиотека, подходящая для работы с большими наборами данных. Отлично работает с динамическими и веб-графиками.
Altair
Легкая и интуитивная библиотека, построенная на основе декларативных спецификаций. Удобна для быстрого создания сложных интерактивных графиков.
Yellowbrick
Расширяет возможности scikit-learn для визуализации моделей, метрик и диагностик. Включает визуализацию обучения, важности признаков и другие функции.
Mayavi
Для 3D-графики, особенно в научных и технических приложениях. Подходит для визуализации поверхностей, полей данных.
TensorBoard
Инструмент от Google для визуализации экспериментов TensorFlow. Удобен для анализа потерь, градиентов и обучения.
Библиотеки для NLP
Hugging Face Transformers
Библиотека Transformers произвела революцию в обработке естественного языка, сделав современные модели доступными для всех. Здесь и BERT, и GPT — в общем, благодаря ей внедрение инновационных технологий стало доступно как никогда.
NLTK и spaCy
NLTK предоставляет комплексные образовательные ресурсы и исследовательскую платформу, а spaCy фокусируется на производительности. Если применять их вместе, то библиотеки закроют весь пул потребностей в NLP — от академических исследований до промышленного применения.
Библиотеки для работы с медицинскими данными
Да-да, биотехнологии сейчас как никогда в тренде. И Python в них, можно сказать, впереди планеты всей. С помощью библиотек и фреймворков исследователи и разработчики могут анализировать сигналы мозга, строить прогнозы для пациентов и использовать AI для улучшения медицинской диагностики. Ниже — о них.

0
MNE
MNE — это незаменимый инструмент для работы с сигналами мозга, такими как магнитоэнцефалография (MEG) и электроэнцефалография (EEG). Он позволяет не только обрабатывать, но и визуализировать сложные временные ряды. Анализ данных мозга стал проще: загружаем файл, настраиваем фильтры и видим всё в наглядных графиках. Отличный выбор для нейрофизиологов и исследователей.
Nilearn
Nilearn делает анализ данных нейровизуализации, таких как fMRI, доступным даже для новичков. Построение тепловых карт активности мозга, изучение соединений и интеграция с машинным обучением через scikit-learn — всё это в одной библиотеке. Инструмент помогает мостить путь от простого анализа до сложных моделей ИИ.
MONAI
Если нужно внедрить глубокое обучение в медицинскую визуализацию, то MONAI — ваш выбор. Построенная на базе PyTorch, эта библиотека идеально подходит для задач сегментации и классификации медицинских изображений. Поддержка форматов DICOM и NIfTI и совместимость с ускорением на GPU делают её незаменимой для медицинских исследований и стартапов.
NiBabel
Когда нужно работать с нейровизуализационными данными и понимать все эти сложные форматы (NIfTI, MINC, Analyze), на помощь приходит NiBabel. Она помогает легко конвертировать и анализировать данные перед дальнейшей обработкой в Nilearn или MNE. Простота использования и мощный функционал — за это её любят исследователи.
Lifelines
Клинические исследования и прогнозирование событий, например, рецидивов или смертности, невозможны без анализа выживаемости. Lifelines предоставляет мощные инструменты для построения каплан-майеровских графиков и моделей Кокса. Простота синтаксиса и визуализация наглядных графиков делают её популярной среди медиков и биостатистиков.
Python в сфере Data Science популярен не просто так. Его применяют в реальных задачах — от анализа поведения пользователей до прогнозирования эпидемий. Инструменты Python делают сложные задачи проще и помогают бизнесу, науке и технологиям развиваться быстрее.