
Каждый день мы используем приложения: отправляем сообщения, ищем информацию и получаем ответы. Для нас это кажется обычным делом, но за кулисами — сложная обработка данных, благодаря которой всё работает быстро и без перебоев.
015 открытий56 показов
Когда нужно создать приложение, которое будет справляться с большим количеством пользователей и данных, разработчики используют подход Pub/Sub (сокращение от англ. Publisher/Subscriber, то есть Издатель/Подписчик). Проще всего сравнить эту модель с рассылкой новостей:
- Издатель — это тот, кто отправляет информацию. Например, новостной сайт.
- Подписчик — это тот, кто подписался и хочет получать информацию. Например, читатель новостного сайта, — он будет получать уведомления о новых статьях.
Pub/Sub помогает создавать надёжные и быстрые приложения, даже если пользователей много. О том, как это работает, читайте ниже.
Что внутри Pub/Sub
Чтобы было проще понять, как устроена архитектура Pub/Sub, приведём простую аналогию. Представьте, что у вас есть канал в Telegram. Автор канала (Publisher) пишет сообщение, а все участники (Subscribers) его получают. Если один из подписчиков покидает канал или кто-то, наоборот, присоединяется, автору ничего не нужно менять — он, как и раньше, публикует посты, уведомления о которых приходят всем, кто подписан на этот канал.
Генерация данных с помощью Python: зачем это нужно и как применятьtproger.ru
Большие приложения состоят из множества независимых частей — микросервисов. Чтобы приложение работало правильно, микросервисы должны быстро обмениваться данными. И как раз для этого разработчики и используют подход Pub/Sub.
Мы уже рассказали об издателях и подписчиках, но в этой архитектуре также участвуют и брокеры (или посредники) — именно они отвечают за доставку сообщений.
Забегая вперёд скажем, что именно брокер обеспечивает масштабируемость в системе. Он организует передачу сообщений и не блокирует выполнение других операций, даже если участников становится очень много. Код брокера обычно пишут на Python или Java, используя при этом дополнительные библиотеки.
Главная идея такая: издатель не знает, кто получит его сообщения, а подписчики не запрашивают эти сообщения напрямую. Всё происходит через посредника. Это работает следующим образом:
- Издатель отправляет сообщение (например, текст или видео) в определённый канал — он называется темой (Topic).
- Получатели подписываются на нужную тему, чтобы принимать эти сообщения.
- Как только сообщение отправлено в тему, все подписчики его получают.
Этот процесс проиллюстрирован на следующей схеме:
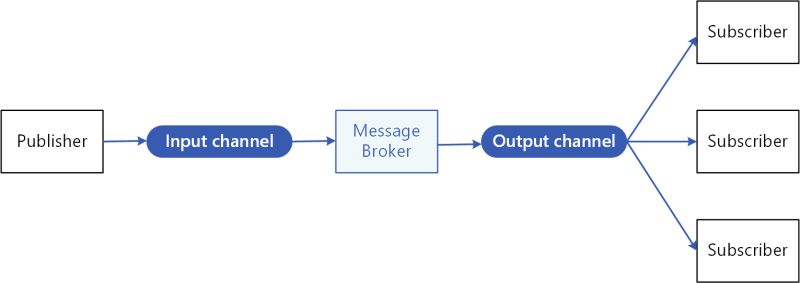
Помимо всех действующих лиц на схеме вы можете увидеть каналы. Input channel — это место, куда издатель отправляет сообщения, а output channel — место, откуда подписчики получают эти сообщения.
Обмен сообщениями происходит асинхронно. Это значит, что отправитель (или издатель) не ждёт, когда получатель (или подписчик) обработает сообщение. Поэтому компоненты приложения могут работать независимо друг от друга, но при этом обмениваться данными.
Паттерн Pub/Sub тем и отличается от стандартных алгоритмов, в которых очередь из сообщений продолжает формироваться, пока пользователи либо службы не сделают запрос и не извлекут их.
Итак, почему же эта архитектура так удобна?
Python-интервью: что спрашивают и как успешно ответитьtproger.ru
Суть в том, что разработчикам не нужно вручную прописывать, кто кому и что отправляет. Например, если издатель опубликовал событие «пользователь сделал заказ», система сама оповестит все нужные сервисы: склад получит команду проверить товар, доставка начнёт планировать маршрут, а клиент получит соответствующее уведомление. И всё это будет происходить параллельно.
Сообщение обязательно дойдёт до всех подписчиков, если они не настроили фильтры, чтобы его игнорировать. Например, если один сервис подписан только на сообщения «заказы», он не будет получать данные из темы «новые пользователи».
Теперь для наглядности приведём пример простого кода брокера.
Пример кода брокера на Python
Код можно написать на разных языках, но для примера мы возьмем Python — просто потому, что его легче понять. Мы используем популярную библиотеку для работы с очередями — asyncio. А чтобы продемонстрировать случайную задержку при обработке сообщений, используем библиотеку random.
import asyncio import random class Broker: def __init__(self): self.topics = {} # Создаём словарь для хранения тем и их подписчиков def subscribe(self, topic, subscriber): """Функция, чтобы подписывать пользователя на тему""" if topic not in self.topics: self.topics[topic] = [] self.topics[topic].append(subscriber) def publish(self, topic, message): """Функция, чтобы отправлять сообщение в тему""" if topic in self.topics: for subscriber in self.topics[topic]: # Отправляем сообщение каждому подписчику asyncio.create_task(subscriber.receive_message(topic, message)) class Subscriber: def __init__(self, name): self.name = name async def receive_message(self, topic, message): """Метод для получения сообщения от брокера""" # Далее — симуляция обработки сообщения await asyncio.sleep(random.uniform(0.5, 2.0)) # Случайная задержка для симуляции обработки print(f"{self.name} получил сообщение на тему '{topic}': {message}") async def main(): # Создаём брокера broker = Broker() # Создаём подписчиков subscriber1 = Subscriber("Пользователь 1") subscriber2 = Subscriber("Пользователь 2") subscriber3 = Subscriber("Пользователь 3") # Подписываем их на тему «заказы» broker.subscribe("заказы", subscriber1) broker.subscribe("заказы", subscriber2) broker.subscribe("заказы", subscriber3) # Издатель отправляет сообщение в тему «заказы» print("Издатель публикует сообщение: Новый заказ!") broker.publish("заказы", "Новый заказ на доставку!") # Подождём, пока все подписчики получат сообщение await asyncio.sleep(3) # Запускаем программы asyncio.run(main())
В коде реализовано всё то, о чём мы говорили выше: когда издатель публикует сообщение, оно мгновенно передаётся всем подписчикам, которые подписаны на соответствующую тему. Далее каждый подписчик асинхронно обрабатывает сообщение (с задержкой, чтобы имитировать реальную работу приложения).
Этот код — очень простой пример реализации брокера. Для более сложных систем, например, с постоянным хранением сообщений, обработкой ошибок и масштабированием, нужна инфраструктура серьёзнее. Для её создания используют внешние брокеры сообщений — те же RabbitMQ или Apache Kafka. Об этом мы рассказываем ниже.
Как выбрать инструменты для реализации Pub/Sub
Как мы уже сказали, брокера для Pub/Sub можно написать на разных языках с использованием дополнительных библиотек. Выбор зависит от масштаба проекта, специфики, количества пользователей.
Рассмотрим наиболее популярные инструменты.
Apache Kafka
Это платформа для обмена данными между приложениями в реальном времени. Она позволяет передавать большие объёмы информации быстро и надёжно — можно не переживать, что данные будут потеряны.
Например, если приложение A хочет отправить данные приложению B, оно не делает это напрямую, а отправляет сообщение в Kafka. Kafka сохраняет эти сообщения и передает их всем заинтересованным приложениям, которые подписались на получение этой информации.
Kafka особенно полезен там, где нужно работать с большими объёмами данных в реальном времени — например, в системах стриминга видео или аналитики. Она может обрабатывать миллионы событий в секунду и гарантирует, что данные не потеряются.
Вот где используют Apache Kafka:
- LinkedIn использует Kafka для передачи сообщений между микросервисами.
- Netflix применяет Kafka для контроля количества событий, обрабатываемых одновременно, и передачи данных из нескольких потоков.
- The New York Times использует Kafka для публикации новостей в режиме реального времени.
Приведём пример простой публикации и получения сообщений (учитывайте, что у вас должна быть установлена соответствующая библиотека и запущен Apache Kafka на локальном сервере или в облаке):
from confluent_kafka import Producer, Consumer # Указываем конфигурацию Kafka KAFKA_BROKER = 'localhost:9092' TOPIC = 'test_topic' # Publisher — он же издатель producer_conf = {'bootstrap.servers': KAFKA_BROKER} def produce_message(): producer = Producer(producer_conf) for i in range(5): message = f'Сообщение {i}' producer.produce(TOPIC, message) print(f'Отправлено: {message}') producer.flush() # Subscriber — подписчик consumer_conf = { 'bootstrap.servers': KAFKA_BROKER, 'group.id': 'test_group', 'auto.offset.reset': 'earliest' } def consume_message(): consumer = Consumer(consumer_conf) consumer.subscribe([TOPIC]) print("Полученные сообщения:") while True: msg = consumer.poll(1.0) # Ожидаем сообщение 1 секунду if msg is None: break if msg.error(): print(f"Ошибка: {msg.error()}") else: print(f'Получено: {msg.value().decode("utf-8")}') # Запуск if __name__ == "__main__": print("Публикация сообщений...") produce_message() print("nЧтение сообщений...") consume_message()
Producer отправляет сообщения в Kafka в определённую тему (в нашем случае — test_topic). Consumer подписывается на эту тему и получает сообщения.
В реальных системах таких издателей и подписчиков может быть много, и Kafka помогает координировать их работу.
RabbitMQ
Это брокер сообщений или посредник, который помогает разным приложениям обмениваться данными. Его разработали в 2007 году на Erlang — языке, который отлично подходит для создания устойчивых к сбоям систем.
RabbitMQ поддерживает несколько протоколов обмена данными, поэтому его можно использовать в разных проектах. Например, он может связывать микросервисы, обрабатывать фоновую информацию и управлять большими объёмами сообщений.
RabbitMQ работает как почтовая служба:
- Одно приложение отправляет сообщение (письмо).
- RabbitMQ принимает это сообщение и сохраняет его в очереди.
- Другое приложение (подписчик) получает сообщение из этой очереди.
Особенность RabbitMQ — push-модель. Брокер сам отправляет сообщения получателю сразу, как только они появляются. Получателю не нужно запрашивать данные постоянно — он просто ждёт, пока RabbitMQ пришлёт новые сообщения.
Эта особенность полезна, когда нужно быстро информировать участников системы о важных событиях. Например, отправлять уведомления о статусе заказа, оповещать системы мониторинга о проблемах или обновлять данные в реальном времени.
Покажем пример (RabbitMQ можно подключить к Python с помощью библиотеки pika):
import pika # Настраиваем подключение к RabbitMQ connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # Создаём очередь для сообщений channel.queue_declare(queue='test_queue') # Отправляем сообщения def publish_message(): message = "Привет, это сообщение из RabbitMQ!" channel.basic_publish(exchange='', routing_key='test_queue', body=message) print(f" [x] Отправлено: {message}") # Получаем сообщения def consume_message(): def callback(ch, method, properties, body): print(f" [x] Получено: {body.decode()}") channel.basic_consume(queue='test_queue', on_message_callback=callback, auto_ack=True) print(' [*] Ожидание сообщений. Для выхода нажмите CTRL+C') channel.start_consuming() # Запуск if __name__ == "__main__": print("Отправляем сообщение...") publish_message() print("nПолучаем сообщение...") consume_message()
Вот как это работает:
Сначала Producer отправляет сообщение в очередь test_queue. Затем Consumer подписывается на эту очередь и получает сообщения. RabbitMQ принимает сообщение и доставляет его получателю сразу после появления в очереди (та самая push-модель).
Redis
Система управления данными, которая поддерживает не только стандартную очередь сообщений, но и паттерн Pub/Sub. Этот инструмент используют для организации обмена сообщениями, при этом он хранит промежуточный контент (например, набранный, но не отправленный текст), управляет базами данных небольших приложений и одностраничных сайтов.
Redis — идеальный выбор для проектов, где важна скорость доставки информации, в том числе в биржевых и финансовых сервисах. Его применяют также для реализации механизма подписок. Вот пример кода:
import redis import time # Подключение к серверу Redis redis_client = redis.StrictRedis(host='localhost', port=6379, decode_responses=True) # Издатель def publisher(): for i in range(5): message = f"Сообщение {i}" redis_client.publish('my_channel', message) # Отправка в канал "my_channel" print(f" [x] Отправлено: {message}") time.sleep(1) # Пауза для демонстрации # Подписчик def subscriber(): pubsub = redis_client.pubsub() # Подписчик подключается к Redis pubsub.subscribe('my_channel') # Подписка на канал "my_channel" print(" [*] Ожидание сообщений. Для выхода нажмите CTRL+C") for message in pubsub.listen(): if message['type'] == 'message': print(f" [x] Получено: {message['data']}") # Запуск if __name__ == "__main__": import multiprocessing # Создаём два процесса: один для издателя, другой для подписчика pub_process = multiprocessing.Process(target=publisher) sub_process = multiprocessing.Process(target=subscriber) sub_process.start() # Запускаем подписчика time.sleep(0.5) # Даём подписчику время подключиться pub_process.start() # Запускаем издателя pub_process.join() sub_process.terminate()
В примере издатель отправляет 5 сообщений с небольшой паузой, а подписчик сразу их получает.
Примеры реализации Pub/Sub
Паттерн используют в сферах, где нужно организовать быстрый обмен информацией между распределёнными компонентами системы. Автоматизация процессов — ключевое направление реализации Pub/Sub.
Рассмотрим наиболее актуальные области применения шаблона.
Мониторинг системы и мгновенная отправка уведомлений
Те самые темы, о которых мы рассказали раньше, создаются для различных категорий данных — например, загрузка процессора, состояние серверов, журналы ошибок. Каждая служба может публиковать свои метрики в топиках, а подписчики (системы визуализации, алерты и дашборды) получают эти данные для обработки.
Вот пример сценария:
- В крупномасштабной системе мониторинга серверов сообщения о сбоях отправляются в специальный канал.
- Система визуализации Grafana или Prometheus подписана на этот канал и сразу обновляет дашборды.
- В случае критического сбоя на основной системе резервный сервер автоматически включается через подписку на ту же тему.
Pub/Sub позволяет внедрить автоматические реакции на определенные события. Например, если загруженность сервера превышает 90%, система может отправить сообщение об аварийном переключении нагрузки или даже автоматически включить дополнительные вычислительные узлы.
IoT (Интернет вещей)
Смарт-устройств становится все больше, и для каждого из них необходимо организовать надёжный метод сбора и передачи информации. Здесь также на помощь приходит Pub/Sub.
Гаджеты могут выступать издателями: они отправляют показания сенсоров, данные о температуре, движении, состоянии и других параметрах на центральный сервер или в облако.
Для лучшего понимания приведём пример:
- Датчики движения отправляют сообщения в тему «Безопасность».
- Подписчик — система управления домом — принимает эти сообщения и отправляет уведомления на мобильное приложение пользователя.
- Тем временем умная лампа подписана на другой канал и автоматически включается по сигналу о движении.
Pub/Sub обеспечивает масштабируемость IoT-систем — новые устройства можно легко подключать к существующим темам, не нарушая работу всей архитектуры.
Резервное копирование
Многим компаниям важно не только хранить информацию, но и организовать надёжное резервное копирование, чтобы уменьшить риски потери данных. Pub/Sub помогает и здесь: можно автоматически собирать и передавать резервные копии данных в облачные хранилища или на резервные серверы. Вот как это может работать:
- Каждую ночь системы баз данных отправляют уведомление в тему «Резервное копирование».
- Подписчик (облачный сервис хранения) получает это сообщение и инициирует процесс копирования данных.
- Если основной сервер недоступен, сообщение передаётся на резервный сервер, который берёт на себя задачу сохранения.
Также Pub/Sub позволяет настроить многоуровневое резервирование: копии данных могут одновременно отправляться на несколько хранилищ, что и позволяет минимизировать риски потери информации.
Преимущества и недостатки использования Pub/Sub
Давайте кратко пройдёмся по основным плюсам этого паттерна:
- Систему легко адаптировать под любое количество пользователей. Новых издателей и подписчиков можно добавлять без потери производительности, а архитектуру тем и посредников менять без затрагивания базовых компонентов.
- Издатели и подписчики работают независимо друг от друга. Это позволяет создавать безопасные, модульные системы, где компоненты не зависят от прямых связей и могут развиваться отдельно.
- Pub/Sub можно использовать с разными языками программирования (например, Python или Java) и интегрировать с различными брокерами сообщений.
- Сообщения доставляются мгновенно, что делает Pub/Sub идеальным решением для сервисов реального времени.
- Сообщения дублируются в хранилищах для гарантированной доставки. Дополнительно обеспечивается проверка подлинности издателей и шифрование данных для защиты информации.
У паттерна есть и недостатки. Он слишком сложен для использования в небольших приложениях, требует грамотной настройки и сопровождения. Если продукт не нуждается в масштабировании, то применение Pub/Sub — неоправданная трата ресурсов. Не всем системам требуется такой уровень сложности и надёжности.
Для потоковой передачи медиафайлов Pub/Sub — не лучший выбор, поскольку работает в асинхронном режиме. Для конференций в формате видео, голосовых коммуникаций по протоколу IP технология не подойдёт.
Итоги
Pub/Sub — это эффективный и сравнительно простой способ организовать обмен данными между компонентами системы. Он лежит в основе работы распределённых приложений с микросервисной архитектурой и обеспечивает передачу информации в реальном времени.
Технология работает асинхронно, что позволяет системе легко масштабироваться и разделять её на независимые модули. Благодаря брокерам сообщений, которые обрабатывают и распределяют данные, приложения не перегружаются, а обмен информацией становится быстрым и безопасным.