
В Точке мы обучаем наших AI-ассистентов, а для этого нужно много данных. В статье расскажу, как быстро собрать информацию практически с любого сайта при помощи фреймворка Scrapy.
025 открытий116 показов
В Точке мы обучаем наших AI-ассистентов, а для этого нужно много данных. В статье расскажу, как быстро собрать информацию практически с любого сайта при помощи фреймворка Scrapy.
Зачем компании собирают данные
Сегодня в интернете более 1 миллиарда сайтов. На великом и ужасном реддите каждый час появляется более 50 000 новых публикаций. На Github уже опубликовано более 300 млн публичных репозиториев. Всё это — открытые данные, которые можно использовать и, главное — собирать. Разумеется, перед этим проверить условия использования сайта, потому что некоторые из них могут запрещать сбор данных.
Зачем это нужно компаниям:
- Анализ рынка: для ритейла это возможность изучить клиентов и конкурентов.
- Мониторинг сайтов вендоров ПО: некоторые компании выкладывают уязвимости в своих продуктах и делятся возможными решениями.
- Создание продукта: собранные данные можно обогатить, прикрутить красивый интерфейс, умный поиск и предложить пользователю новое приложение, типа 2GIS.
- Развитие LLM: например, Google в 2024 году заключил контракт с Reddit на сбор данных. Open AI тоже часто говорят о том, что обучают свою модель на открытых источниках, а в ближайшее время хотят подключить ещё и транскрибации с YouTube.
Как вы поняли, в интернете очень много данных. И если мы хотим их собрать, то нам нужен подходящий инструмент.
Что такое Scrapy
Это высокоуровневый фреймворк на Python для краулинга и скреппинга сайтов. На GitHub у него больше 53 тысяч звёздочек, 10,6 тысяч форков и много глазиков. А ещё он занимает первое место по тегам #crawling и #scraping.
Есть много причин, почему Scrapy так популярен:
- Это фреймворк с готовой архитектурой — там много инструментов, доступных из коробки, которые можно настроить и использовать.
- Он асинхронный — чаще возникает задача замедлить его, чем ускорить.
- У него простые настройки — нужно всего раз подумать над архитектурой, а добавление новых источников будет занимать минимум времени.
- Scrapy удобно дебажить в любой момент, начиная от загрузки страницы и заканчивая сохранением данных в базе.
- Есть продуманные селекторы, доступны CSS, Xpath. Их можно комбинировать или выбрать что-то одно.
- Большое комьюнити и обновляемая документация. Ответы на большинство вопросов можно легко найти в сети.
Scrapy точно подойдёт вам, если во всех ваших источниках одинаковый формат данных и вы можете унифицировать их обработку и сохранение. Но всё-таки его нельзя назвать универсальным инструментом.
Google запустила тестирование «убийцы» Sora от OpenAI. Насколько ее генерации лучше?tproger.ru
Scrapy будет не лучшим выбором, если:
- Нужно собрать малый объем данных или собрать их нужно всего один раз.
- Вам нужно отдать просто сырые html или json, а не парсить и преобразовывать данные.
- Среди источников нет общей структуры данных.
Во всех этих случаях мы можем использовать Scrapy, но, скорее всего, он будет излишним.
Как работает Scrapy
После того, как вы установили Scrapy в виртуальное окружение ( ” pip instal scrapy’ ) и создали новый проект ( ‘ scrapy startprogect scraper ” ), вам необходимо написать своего первого «паука».
В Scrapy используется класс spider — он определяет, как мы будем извлекать данные из сайтов. Допустим, нам нужно собрать информацию с одностраничного сайта. Создаём класс TestSpider, наследуемся от scrapy.Spider, добавляем атрибут name с уникальным именем и start_urls, где укажем страницы, с которых нужно начать поиск. После этого переопределим метод parse.
class TestSpider(scrapy.Spider): name = "test" start_urls = ["https://test.ru/"] def parse(self, response: scrapy.http.Response):
Parse является дефолтным для обработки ответов. Если вы сделаете request и не укажете функцию, которая должна его обработать, то ответ от запроса придёт в метод parse. Поэтому его, как минимум, нужно переопределить и назначить логику.
Допустим, нас интересует информация о компании — название и описание. Можем создать объект данных с двумя элементами — title и content, и с помощью двух xpath селекторов забрать со страницы заголовок и описание.
class TestSpider(scrapy.Spider): name = "test" start_urls = ["https://test.ru/"] def parse(self, response: scrapy.http.Response): item = { "title": response.xpath("//h1/text()").get() "content": response.xpath("//section//text()").get() } yield item
В конце передаём этот объект данных для последующей обработки в ядро. Это всё, что нужно, чтобы начать парсинг на Scrapy.
Обработка данных в Scrapy
Дальше в ход вступает PipeLine. Он отвечает за обработку данных, валидацию или сохранение. В Scrapy есть пайплайны, готовые из коробки, но вы также можете написать их самостоятельно.
Microsoft анонсировала аналог AirDrop для связки Windows + iPhonetproger.ru
В ValidatePipeline мы проверяем объект данных на наличие title, а в SavePipeline — сохраняем объект в качестве json.
class ValidatePipeline: def process_item(self, item: dict, spider: scrapy.Spider): if not item>get("title"): raise DropItem(f"Missing title in {item}") return item class SavePipeline: def process_item(self, item: dict, spider: scrapy.Spider): new_file: Path = CURRENT_DIR / f"{item['title']}.json" json_data: str = json.dumps(item) new_file.write_text(json_data) return item
Здесь я просто показал, как можно создать пайплайн самостоятельно. Но имейте в виду, что это не очень отказоустойчивый код, поэтому в проде так делать не стоит.
Зачем нужен Middleware
Middleware очень похож на PipeLine, только он обрабатывает не объекты данных, а запросы и ответы от сайта.
В Scrapy есть несколько разных middleware:
- scheduler middleware: помещает запросы в очередь и извлекает их для обработки.
- spider middleware: управляет данными между пауком и ядром.
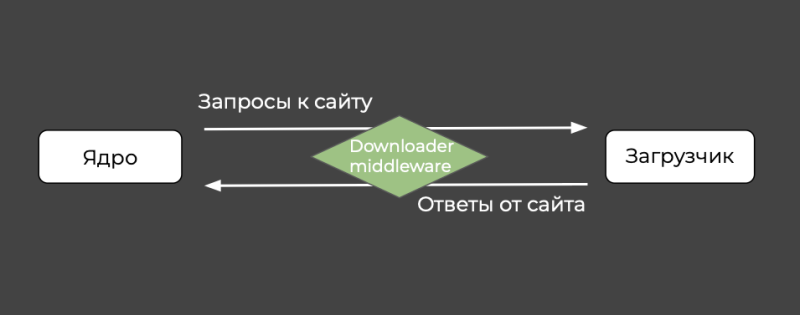
- downloader middleware: управляет данными между ядром и загрузчиком.
Получается такая схема работы компонентов Scrapy:
Запрос: Spider → Spider Middleware → Engine → Scheduler Middleware → Scheduler → Engine → Downloader Middleware → Downloader → Server (сайт)
Ответ: Server → Downloader → Downloader Middleware → Engine → Spider Middleware → Spider → Item Pipeline → Storage (хранилище данных)
Скорее всего, в первую очередь вы будете настраивать downloader middleware, поэтому разберём его подробнее.
Ниже продемонстрировал два примера, как можно написать свой Middleware. В RandomProxyMiddleware мы обрабатываем все запросы, которые будет отсылать наш паук с помощью метода process_request (добавляем рандомную прокси к каждому реквесту), а в CheckCaptchaMiddleware — обрабатываем все ответы с помощью метода process_response (проверяем ответ от сайта, ищем в нём слово captcha).
class RandomProxyMiddleware: def process_request(self, request, spider): request.meta["proxy"] = random.choice(PROXY_LIST) class CheckCaptchaMiddleware: def process_response(self, request, response, spider): if "captcha" in response.text: return solve_captcha(response) return response
Итак, мы написали Pipeline и Middlewares. Дальше нужно указать, как мы будем их использовать. Для этого запишите их в файле settings.py, где находятся настройки проекта.
Начнём с пайплайнов. Цифра справа — это порядковый номер выполнения. То есть первым будет ValidatePipeLine, а вторым сработает SavePipeline. Обычно цифры указываются от 0 до 1000. И в случае с пайплайнами чем ниже цифра, тем раньше сработает пайплайн.
ITEM_PIPELINES = { "scraper.pipelines.ValidatePipeline": 1, "scraper.pipelines.SavePipeline": 2, }
В случае с middleware картина такая же, но логика немного иная.
DOWNLOADER_MIDDLEWARES = { "scraper.middlewares.RandomProxyMiddleware": 1, "scraper.middlewares.CheckCaptchaMiddleware": 2, }
Каждый middleware может обрабатывать как request, так и response. При этом middleware стоит посередине между ядром, который отправляет запросы, и загрузчиком. Если ваша middleware обрабатывает запросы, то сработает первой та, что указана с меньшей цифрой, потому что она ближе к ядру. А если middleware обрабатывает ответы, то первой будет та, у которой цифра больше, потому что она дальше от ядра и ближе к загрузчику.
Об этот нюанс часто спотыкаются новички, хотя, скорее всего, он прописан в документации.
Пример, как использовать Scrapy
Рассмотрим, как с помощью одного селектора собрать сайт любой вложенности и архитектуры.
Для начала создаём класс паука, наследуемся от scrapy.Spider, указываем name, start_urls и атрибут allowed_domains — он необязательный, но в данном случае без него не обойтись. В нём мы укажем список хостов, на которые разрешаем ходить нашему пауку, чтобы он не начал собирать другие сайты.
class TestSpider(scrapy.Spider): name = "test" start_urls = ["https://test.ru/"] allowed_domains = ["test.ru"]
Дальше переопределяем метод parse и, когда к нам приходит ответ от сайта, находим все ссылки. И это и есть тот единственный xpath селектор, который поможет обойти весь сайт и собрать страницы.
Все ссылки помещаем в переменную url в качестве списка, а потом этот список передаём в функцию follow_all объекта response.
Чтобы дописать сохранение, просто передаём объект response вглубь ядра Scrapy, где напишем какой-то нехитрый пайплайн и будем сохранять html-страницы. Так можно собрать абсолютно любой сайт, просто подставьте ссылку на него в start_urls.
class TestSpider(scrapy.Spider): name = "test" start_urls = ["https://test.ru/"] allowed_domains = ["test.ru"] def parse(self, response: scrapy.http.Response) urls = response.xpath("//a/@href").getall() yield from response.follow_all(urls) yield {"response": response}
Важный нюанс: под капотом follow_all сделает запросы к сайту по всем ссылкам, которые мы нашли на странице. И поскольку в follow all мы не указываем определённый метод в параметре callback, то все ответы придут сюда же в метод parse (потому что он дефолтный в Scrapy). Эта логика будет повторяться на каждой странице.
Ещё в Scrapy есть внутренний фильтр, поэтому если паук соберёт дубликаты, то автоматически зафильтрует их и не будет проходить по ссылкам дважды.
Немного итогов
Scrapy — это большой, сложный, но очень хороший фреймворк, как Django в веб-разработке. Он предлагает большой выбор готовых инструментов для сбора и обработки данных, а также, поддерживает асинхронное выполнение задач, что ускоряет процесс парсинга.
Scrapy может показаться трудным для новичков, но у него есть богатая документация и примеры, поэтому при желании в нём нетрудно разобраться.