
Рассказываем, что такое хэш-таблицы и как с ними работать.
180 открытий323 показов
Представьте, что вам нужно мгновенно находить нужные данные среди миллионов записей — например, определять, есть ли пользователь в базе, или быстро подсчитывать количество посещений страницы. Обычный массив или список справится с этим за O(n), а хэш-таблица — за O(1) в среднем.
Но как устроена эта мощная структура данных? Почему программисты так активно используют её в Python, Java и C++? И какие нюансы нужно учитывать при работе с хэш-таблицами, чтобы избежать коллизий и потерь производительности?
В этом материале разберем, как работает хеш-таблица, какие у неё преимущества и недостатки, и как её эффективно использовать в своих проектах.
Как работают хэш-таблицы?
Принцип хэширования: что такое хэш-функция и как она работает
Ключевая идея хэш-таблицы — преобразование ключа в индекс с помощью специальной функции, называемой хэш-функцией.
Хэш-функция — алгоритм, который берет входные данные (например, строку) и преобразует их в числовое значение фиксированной длины. Это значение называется хэш.
Пример работы хэш-функции:
def simple_hash(key, size): return sum(ord(char) for char in key) % size print(simple_hash("Python", 10)) # Например, результат: 6
В этом коде мы берем сумму ASCII-кодов символов ключа, а затем берем остаток от деления на размер таблицы:
- Ключ (например, строка “Python”) передается в хэш-функцию.
- Функция вычисляет индекс (например, 6), куда будет помещено значение.
- Если нужно найти значение по ключу, хэш-функция снова вычислит индекс и возвратит нужные данные.
Такой подход позволяет избежать перебора всех элементов, как это происходит в списках, и сразу обращаться к нужному индексу.
Структура: массив и связка ключ-значение
Хэш-таблицы устроены достаточно просто: в основе лежит массив, в котором хранятся пары ключ-значение. Именно эта структура данных позволяет использовать хэширование для быстрого доступа к элементам.
- Ключ — уникальный идентификатор элемента, который передается в хэш-функцию.
- Значение — информация, привязанная к ключу (например, число, строка или объект).
- Хэш-функция — преобразует ключ в индекс массива, по которому будет храниться значение.
Представим, что у нас есть хэш-таблица на 5 ячеек:
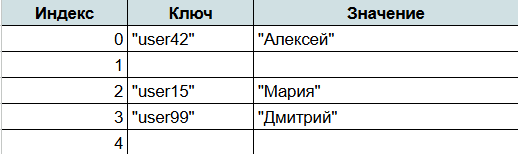
Если мы захотим получить имя “user15”, хэш-функция найдет индекс 2, и поиск займет O(1).
Использование массива позволяет быстро находить нужное значение. В отличие от списков, где поиск требует O(n) операций, в хэш-таблицах поиск идет за O(1) мгновенно.
Но если происходит коллизия (два ключа получают один индекс), приходится использовать дополнительные структуры, например, связные списки.
Основные операции с хэш-таблицами
Хэш-таблицы используют три основные операции:
- Вставка элемента (Insert). Добавление новой пары ключ-значение.
- Поиск элемента (Search). Быстрый доступ к значению по ключу.
- Удаление элемента (Delete). Удаление пары ключ-значение.
Рассмотрим, как работает каждая из них.
Вставка элемента (Insert)
Когда мы создаем новую запись в хэш-таблице, происходит следующее:
- Хэш-функция вычисляет индекс для ключа;
- Если ячейка свободна, значение записывается в массив;
- Если ячейка занята (коллизия), используется стратегия разрешения коллизий.
В Python использовать хэш-таблицы просто: достаточно добавить элемент в dict:
users = {} # Создаем пустую хеш-таблицу # Вставляем элементы users["user42"] = "Алексей" users["user15"] = "Мария" print(users) # {'user42': 'Алексей', 'user15': 'Мария'}
Здесь “user42” — ключ, а “Алексей” — значение. Python автоматически рассчитывает индекс и записывает значение.
Поиск элемента (Search)
Поиск — одна из главных причин использовать хэш-таблицы. В отличие от списков, где поиск требует O(n), в хэш-таблицах он занимает O(1).
Как работает поиск:
- Хэш-функция вычисляет индекс для ключа;
- По индексу извлекается значение;
- Если индекс занят другим ключом (из-за коллизии), выполняется проверка (например, в связанном списке).
Пример:
print(users.get("user15")) # Выведет: Мария
Использование get() позволяет избежать ошибки, если ключ отсутствует.
Удаление элемента (Delete)
При удалении элемента:
- Находится индекс по хэш-функции;
- Элемент удаляется, а ячейка либо помечается как пустая, либо применяется специальная стратегия (например, сдвиг элементов).
Пример:
del users["user42"] # Удаляем ключ "user42" print(users) # {'user15': 'Мария'}
Если ключа нет, del вызовет ошибку. Поэтому можно использовать pop():
users.pop("user42", "Ключ не найден") # Без ошибки, если ключа нет
Преимущества и недостатки хэш-таблиц
Хэш-таблицы — мощная структура данных, но у нее есть как сильные, так и слабые стороны.
Быстрые операции (в среднем O(1))
Главное преимущество хэш-таблиц — быстродействие. Вставка, поиск и удаление элементов происходят в среднем за O(1). Это означает, что независимо от количества элементов, доступ к данным остается мгновенным.
Например, если в обычном списке для поиска элемента придется перебрать все элементы (O(n)), то в хэш-таблице достаточно вычислить хэш и сразу найти нужное значение.
Простота использования
В Python использовать хэш-таблицы легко: стандартный dict уже реализует все основные операции:
users = {"id_1": "Мария", "id_2": "Алексей"} print(users["id_1"]) # Выведет: Мария
В отличие от других структур, здесь не нужно заботиться о реализации алгоритмов поиска и хранения.
Возможные коллизии
Несмотря на эффективность, у хэш-таблиц есть слабое место — коллизии.
Коллизия возникает, когда разные ключи получают одинаковый хэш и пытаются занять одно и то же место в массиве:
def bad_hash(key): return len(key) # Примитивная хеш-функция ht = {} ht[bad_hash("cat")] = "кот" ht[bad_hash("dog")] = "собака" print(ht) # {'3': 'собака'} - Значение "кот" перезаписано
Из-за плохой хэш-функции “cat” и “dog” получили одинаковый хэш, и одно значение затерло другое. Чтобы избежать коллизий, используют методы вроде цепочек (связных списков) или открытой адресации.
Необходимость в эффективной хэш-функции
Чем лучше хэш-функция, тем меньше вероятность коллизий.
Популярные ошибки в Golang и как их избежатьtproger.ru
Хорошая хэш-функция должна:
- Распределять данные равномерно по таблице;
- Быть быстрой в вычислениях;
- Минимизировать число одинаковых хэшей для разных ключей.
Затраты на память
Хэш-таблицы требуют больше памяти, чем массивы или списки.
Чтобы избежать коллизий и обеспечивать O(1)-доступ, хэш-таблицы используют больше места, чем реально хранят данных. Например, если таблица заполнена на 70-80%, скорость работы снижается, и приходится увеличивать размер массива (ресайзинг).
Примеры использования хэш-таблиц
Хэш-таблицы широко применяются в программировании благодаря их скорости и удобству. Рассмотрим несколько популярных сценариев их использования в реальных задачах.
Кеширование данных (Memoization)
Хеш-таблицы помогают ускорить вычисления, сохраняя уже найденные результаты. Это особенно полезно при решении задач динамического программирования.
Пример — ускоренное вычисление чисел Фибоначчи:
fib_cache = {} def fibonacci(n): if n in fib_cache: # Проверяем кеш return fib_cache[n] if n <= 1: return n fib_cache[n] = fibonacci(n - 1) + fibonacci(n - 2) return fib_cache[n] print(fibonacci(50)) # Мгновенный результат вместо долгих вычислений
Подсчет частоты слов в тексте
Хэш-таблицы удобно использовать для анализа текстов, например, для подсчета количества повторений слов.
Пример — частотный словарь:
text = "хеш таблицы используются в программировании очень часто" word_count = {} for word in text.split(): word_count[word] = word_count.get(word, 0) + 1 print(word_count) # {'хеш': 1, 'таблицы': 1, 'используются': 1, ...}
В хеш таблицу сразу записываются все слова с их количеством — никакие циклы в массиве не нужны.
Уникальные элементы в списке
Хэш-таблицы можно использовать для удаления дубликатов в массиве.
Пример:
numbers = [1, 2, 3, 4, 1, 2, 5, 6] unique_numbers = list(set(numbers)) # set использует хеш-таблицу print(unique_numbers) # [1, 2, 3, 4, 5, 6]
Проверка наличия элементов (поиск в больших массивах)
Хэш-таблицы часто используют для быстрой проверки, содержится ли элемент в массиве.
Пример — проверка наличия логина:
usernames = {"Мария", "Алексей", "Александр"} # set использует хеш-таблицы print("Мария" in usernames) # True (O(1)) print("Андрей" in usernames) # False
Хэш-таблицы в популярных языках программирования
Хэш-таблицы — неотъемлемая часть многих языков программирования, и реализация может отличаться в зависимости от выбранного инструмента. Рассмотрим, как таблицы устроены в Python, Java и C++, а также сравним особенности.
Python: dict
В Python стандартная хэш-таблица реализована через встроенный тип dict. Это одна из самых оптимизированных структур данных в языке, обеспечивающая O(1) доступ к элементам в среднем случае.
Пример использования:
phone_book = { "Мария": "+7-999-999-0000", "Александр": "+7-999-999-0001", "Алексей": "+7-999-999-0002" } print(phone_book["Мария"]) # +7-999-999-0000
Особенности dict в Python:
- Основан на открытой адресации для разрешения коллизий;
- Гарантирует порядок вставки (с версии Python 3.7+);
- Автоматически увеличивает размер при заполнении;
- Поддерживает defaultdict из collections для значений по умолчанию.
Java: HashMap
В Java для реализации хэш-таблицы чаще всего используют класс HashMap. Он не гарантирует порядок элементов, но обеспечивает быструю вставку и поиск.
Пример использования:
import java.util.HashMap; public class Main { public static void main(String[] args) { HashMap phoneBook = new HashMap<>(); phoneBook.put("Мария", "+7-999-999-0000"); phoneBook.put("Александр", "+7-999-999-0001"); System.out.println(phoneBook.get("Мария")); // +7-999-999-0000 } }
Особенности HashMap в Java:
- Использует цепочечное хэширование (chaining) для обработки коллизий;
- Не сохраняет порядок элементов (используйте LinkedHashMap, если порядок важен);
- Может хранить null в качестве ключа;
- В Java 8+ при большом числе коллизий список заменяется на дерево, что улучшает производительность.
C++: unordered_map
В C++ стандартная хэш-таблица представлена контейнером unordered_map, который входит в STL (Standard Template Library).
Пример использования:
#include #include int main() { std::unordered_map phoneBook; phoneBook["Мария"] = "+7-999-999-0000"; phoneBook["Александр"] = "+7-999-999-0001"; std::cout << phoneBook["Мария"] << std::endl; // +7-999-999-0000 return 0; }
Особенности unordered_map в C++:
- Использует цепочечное хэширование (chaining) для обработки коллизий;
- Не сохраняет порядок элементов;
- Позволяет определять собственные хэш-функции;
- В среднем обеспечивает O(1) на поиск, вставку и удаление.
Если сравнивать особенности реализации, то:
- Когда нужен порядок вставки → Python dict или Java LinkedHashMap.
- Когда важна скорость без дополнительных затрат → unordered_map в C++.
- Когда нужна безопасность при большом числе коллизий → Java HashMap (начиная с Java 8+ использует деревья для баланса).
Советы по использованию хэш-таблиц
Хэш-таблицы — мощный инструмент для быстрого доступа к данным, но их эффективность во многом зависит от контекста использования, выбора хэш-функции и грамотного управления памятью. В этом разделе разберем основные рекомендации.
Когда стоит использовать хэш-таблицы?
Использование хэш-таблиц оправдано в ситуациях, где важны:
- Быстрый поиск — доступ к элементу в O(1) (в среднем).
- Частая модификация — вставка и удаление быстрее, чем в массивах и сбалансированных деревьях.
- Ассоциативные отношения — когда данные хранятся в формате «ключ-значение».
Но когда НЕ стоит использовать хэш-таблицы:
- Если важен порядок элементов (лучше использовать TreeMap в Java или OrderedDict в Python).
- Если хеш-таблица будет сильно заполнена (может возникнуть деградация до O(n) при поиске).
- Если требуется эффективный диапазонный поиск (лучше использовать деревья, например, std::map в C++).
Как выбрать или написать свою хэш-функцию?
Хорошая хэш-функция должна обладать следующими свойствами:
- Равномерное распределение — минимизация коллизий;
- Быстродействие — должна вычисляться за O(1);
- Детерминированность — один и тот же ключ всегда дает один и тот же хэш.
Оптимальным вариантом здесь будет:
- Если используете таблицы в Python — стандартная хэш-функция hash() в сочетании с dict.
- В Java можно переопределить метод hashCode() в классах.
- В C++ можно задать свою std::hash<> или использовать криптографические методы (SHA-256, MD5).
Учет размера хэш-таблицы и предотвращение избыточного заполнения
Хэш-таблицы динамически увеличиваются, но важно следить за балансом между скоростью работы и расходом памяти.
Основные правила:
Коэффициент загрузки (Load Factor) — отношение заполненных ячеек к общему размеру таблицы.
- В Python dict увеличение происходит при заполнении на 2/3.
- В Java HashMap по умолчанию увеличение происходит при загрузке более 75%.
- В C++ unordered_map поведение зависит от конкретной реализации.
Также используйте простые числа для размеров таблицы — это снижает количество коллизий.
Если таблица работает медленно, проверьте коллизии:
- Возможно, стоит заменить хэш-функцию.
- Или использовать TreeMap (Java) или std::map (C++) при частых коллизиях.
Если следовать этим рекомендациям, хэш-таблицы станут мощным инструментом в вашем арсенале!