Рассказываем, каким технологиями по работе с большими данными пользоваться в 2025 году.
121 открытий82 показов
Большие данные — не просто модное слово, которое сейчас звучит из каждого утюга. Это один из главных инструментов для более глубокой аналитики спроса, принятия стратегически правильных решений и прогнозирования будущих тенденций в проекте.
IoT, искусственный интеллект и облачные решения развиваются каждый день. Объёмы информации, с которой необходимо работать, только растут. А значит, появляется новая задача — научиться работать с информацией для прогнозирования всех возможных изменений и увеличения продаж.
Сегодня рассмотрим 5 главных Big Data решений, которые стоит изучить каждому, кто хочет развивать себя и свой проект.
Apache Kafka
Apache Kafka называют «почтальоном» в мире IT. Это система-брокер для потоковой передачи данных с открытым исходным кодом.
Что изучать начинающему разработчику на C#tproger.ru
Проект разработан инженерами LinkedIn в 2010 году при поддержке фонда Apache Software Foundation. Kafka предназначена для работы с данными в реальном времени. При этом сохраняется высокая скорость передачи при минимальных задержках — и это одна из причин, почему распределённую систему так любят.
Apache Kafka используют 80% компаний из списка Fortune 100: например, с технологией работают 10 из 10 компаний в сфере производства и страхования.
Система используется для создания конвейеров потоковых данных и приложений потоковой аналитики. Kafka хороша тем, что обеспечивает бесперебойную доставку сообщений.
Пример кода на Python с использованием библиотеки kafka-python для отправки и получения информации:
from kafka import KafkaProducer, KafkaConsumer producer = KafkaProducer(bootstrap_servers='localhost:9092') producer.send('my-topic', 'Hello, Kafka!') consumer = KafkaConsumer('my-topic', bootstrap_servers='localhost:9092') for message in consumer: print(f'Received message: {message.value.decode()}')
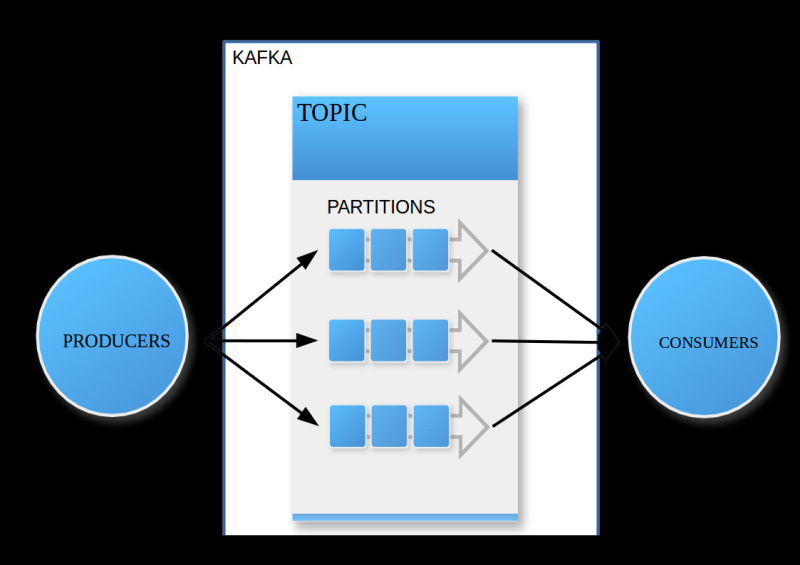
Тот, кто создаёт сообщения — producer, а тот, кто их получает, — consumer. Topic — это темы (другими словами, группы), куда поступают сообщения. Все подписчики (consumers) «вступают» в нужные им темы и после получения сообщений получают уведомления.
Ещё один плюс системы — простая масштабируемость без потери производительности, сколько бы источников одновременно ни обрабатывалось. Это особенно важно для компаний, которые собирают и анализируют информацию сразу из нескольких источников.
А ещё Kafka хороша тем, что автоматически сохраняет все данные на сервере — если что-то сломается или перестанет работать, сообщения все равно сохранятся.
Kafka часто используется для:
- Системы мониторинга приложений для оперативной реакции на изменение данных о системе;
- Аналитики действий пользователей;
- Обработки данных от подключенных устройств для контроля состояния оборудования.
Apache Spark
Apache Spark — фреймворк для обработки больших данных. Платформа популярна благодаря своей высокой производительности и гибкости.
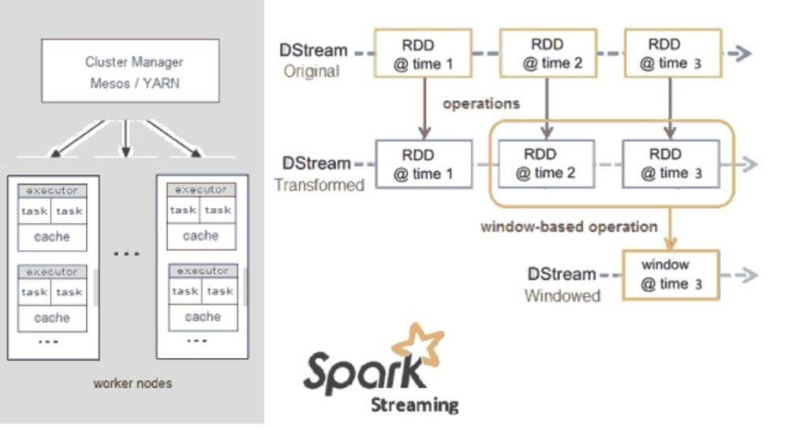
Структура Apache Spark
В 2025 году Spark продолжает оставаться одной из главных технологий в обработке данных. Особенно когда речь идёт об интеграции данных с ML и аналитикой.
Одна из особенностей Apache Spark — способность быстро обрабатывать большие массивы данных с помощью использования памяти для хранения промежуточных вычислений. Например, задачи, которые занимают часы в Hadoop MapReduce, в Spark можно выполнить за несколько минут.
Какие JS-библиотеки использовать для анимаций на сайте в 2024 годуtproger.ru
Пример кода на Python с использованием PySpark для обработки данных:
from pyspark.sql import SparkSession spark = SparkSession.builder.appName("BigData2025").getOrCreate() data = spark.read.csv("data.csv", header=True, inferSchema=True) filtered_data = data.filter(data["age"] > 30) filtered_data.show()
Здесь выполняются 5 этапов работы: выгрузка данных из Spark сессии, создание самой сессии, загрузка данных из CSV-файла, фильтрация данных и отображение результата.
Apache Spark предоставляет инструменты для интеграции с библиотеками ML и аналитики. MLlib — библиотека машинного обучения, встроенная в Spark. С помощью нее можно проводить сложные анализы и создавать модели:
from pyspark.ml.regression import LinearRegression feature_cols = ['feature1', 'feature2', 'feature3'] vectorAssembler = VectorAssembler(inputCols=feature_cols, outputCol='features') data_transformed = vectorAssembler.transform(data) train_data, test_data = data_transformed.randomSplit([0.7, 0.3]) lr = LinearRegression(featuresCol='features', labelCol='label') lr_model = lr.fit(train_data) test_results = lr_model.evaluate(test_data) print(f"RMSE: {test_results.rootMeanSquaredError}")
Здесь описано 5 основных действий при создании модели линейной регрессии: импорт данных с сайта, подготовка данных для обучения, разделение данных на обучающие и тестовые, создание и обучение моделей регрессии и тестовая оценка модели.
Snowflake
Snowflake — это DaaS (Desktop as a Service) решение для работы с данными. Платформа помогает с хранением, обработкой и аналитикой данных — и всё это в одном облачном решении.
С помощью Snowflake можно решать одновременно несколько задач, связанных с большими данными, обеспечивая при этом высокую производительность и масштабируемость. Все пользователи платформы могут легко загружать, хранить и управлять данными в облаке без физической инфраструктуры. А это неплохо экономит деньги.
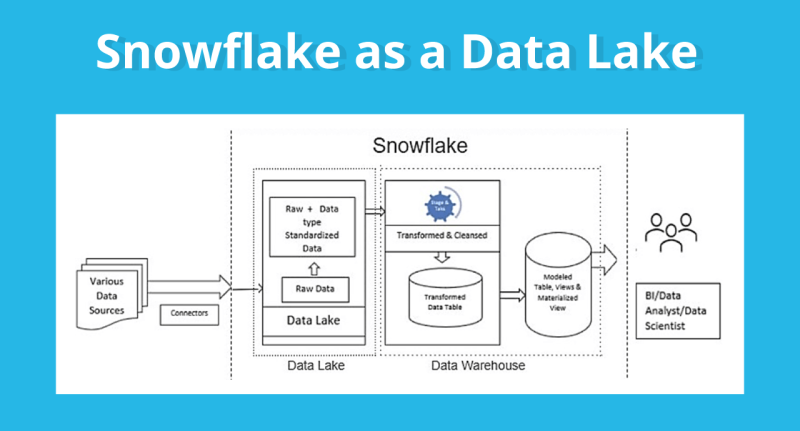
Принцип работы Snowflake
Главный принцип работы Snowflake можно объяснить так: это система, которая предоставляет виртуальные «рабочие столы», где можно хранить и работать с любой загруженной информацией. А ещё данными можно обмениваться с любым количеством пользователей в реальном времени через Snowflake Data Share.
С помощью безопасного подключения к Data Lake можно извлекать неограниченное количество данных из любых источников и потом их анализировать с помощью других инструментов. Это важно для аналитики и принятия стратегических решений в компании.
Ключевое преимущество Snowflake в гибкости. Система сама увеличивает и уменьшает мощность вычислительных ресурсов без прерывания работы. Фактически это динамическая система, которая сама подстраивается под объёмы данных. При этом, количество запросов в обработке не ограничено.
С помощью Snowflake можно выполнять сложные аналитические запросы в несколько кликов. Пример использования Snowflake для анализа больших данных:
USE WAREHOUSE my_warehouse; USE DATABASE my_database; USE SCHEMA public; COPY INTO my_table FROM 's3://mybucket/data/' CREDENTIALS=(AWS_KEY_ID='your_key_id' AWS_SECRET_KEY='your_secret_key') FILE_FORMAT = (TYPE = 'CSV' FIELD_OPTIONALLY_ENCLOSED_BY='"'); SELECT category, COUNT(*) as total_sales FROM sales_data GROUP BY category;
Здесь описано 4 этапа: подключение к Snowflake, загрузка данных из облака, выполнение запроса и отображение результата.
Delta Lake
Delta Lake — это фреймворк для хранения данных, с помощью которого можно создавать архитектуру Lakehouse. Платформа работает с 12 движками (в том числе с Snowflake, Spark и Google BigQuery) для Scala, Java, Rust и Python.
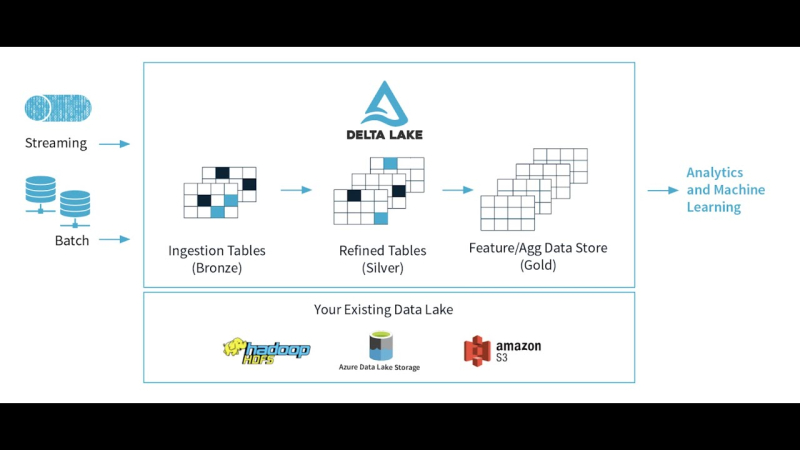
Принцип работы Delta Lake
Традиционные хранилища данных имеют много ограничений, которые мешают управлению и анализу больших массивов информации:
- У обычных хранилищ данных нет единого источника истины, что гарантирует несогласованность данных;
- Традиционные системы не справятся с большими объёмами потоковых данных;
- Для того, чтобы масштабировать обычные системы, нужно потратить много времени и денег. Это дни доработок.
Delta Lake решает эти проблемы с помощью собственной архитектуры на базе Apache Spark. О плюсах Apache Spark мы говорили выше, если коротко: бесперебойное получение информации вне зависимости от объёма данных.
Кроме того, Delta Lake работает и с ACID-транзакциями (транзакции, для выполнения которых важны 4 главных требования: атомарность, согласованность, изолированность, долговечность — АСИД / ACID). А это значит, что данные будут «целыми» и будут передаваться даже при высоких нагрузках.
С помощью Delta Lake можно управлять данными в гибридных средах — средах с разными источниками информации и интеграцией различных типов данных.
Ещё к плюсам решения можно отнести:
- Поддержку разных форматов данных (Parquet, JSON);
- Возможность работы как на локальных серверах, так и в облаке;
- Оптимизацию чтения и записи благодаря архитектуре Apache Spark.
Пример кода на Python с использованием Delta Lake для чтения и записи данных:
from pyspark.sql import SparkSession spark = SparkSession.builder .appName("DeltaLakeExample") .getOrCreate() delta_table = spark.read.format("delta").load("/path/to/delta-table") delta_table_filtered = delta_table.filter(delta_table["value"] > 100) delta_table_filtered.write.format("delta").mode("overwrite").save("/path/to/delta-table") spark.stop()
Здесь описано 6 этапов работы: импорт Spark-сессии, создание сессии, чтение данных из таблицы, выполнение преобразования данных, запись преобразованной информации в таблицу и завершение Spark-сессии.
Google BigQuery
Google BigQuery — сервис для анализа больших данных на базе SQL. Одно из главных преимуществ BigQuery — возможность обрабатывать большие объёмы практически в реальном времени.
Например, BigQuery можно использовать для анализа поведения пользователей на сайтах, обработки потоков данных, IoT и оптимизации цепочек поставок программного обеспечения (SSP).
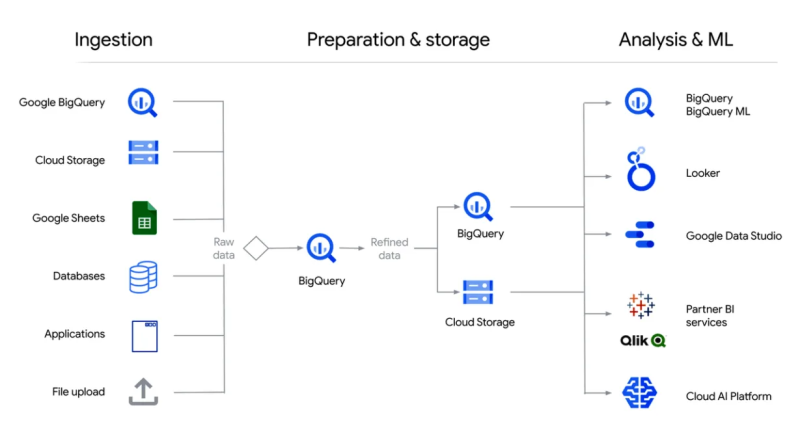
Принцип работы Google BigQuery
Систему можно интегрировать с любыми решениями экосистемы GCP, например, Google Data Studio для визуализации или TensorFlow для машинного обучения.
Ещё один плюс BigQuery — уникальная архитектура, где предусмотрено разделение хранения данных и вычислительных функций. А значит, пользователь платформы платит только за те ресурсы, которыми он фактически пользуется.
В системе можно хранить до 10 гибибайтов (GiB) данных и запускать до 1 тебибайта (TiB) запросов в месяц на бесплатном тарифе. При этом масштабировать систему данных можно без необходимости «ручной» работы. И всё это на базе SQL.
Пример использования Google BigQuery для вывода и анализа данных о продажах:
SELECT product_id, COUNT(*) AS total_sales, SUM(sale_amount) AS total_revenue FROM `project_id.dataset_id.sales` WHERE sale_date BETWEEN '2025-01-01' AND '2025-12-31' GROUP BY product_id ORDER BY total_revenue DESC LIMIT 10;
Советы по изучению технологий
Большие данные требуют от специалистов постоянного обучения и адаптации к новым инструментам и методам. Здесь мы расскажем, как изучать технологии больших данных, какие ресурсы использовать и на что важно обращать внимание.
Ресурсы для обучения
- Один из лучших способов изучить новую технологию — обратиться к официальной документации. Например, для Apache Spark или Google BigQuery документация поможет не только понять принцип работы решений в теории, но и на практике.
- Курсов по Big Data становится всё больше и больше. Помним о том, что не всем понравились зарубежные курсы по программированию, поэтому советуем российские 🙂 МИПО, Яндекс.Практикум, ProductStar — все они предлагают хорошие курсы в направлении Data Science.
- Ещё один эффективный способ освоить Big Data — практика. Участвуйте в конкурсах и тематических мероприятиях или работайте над собственными проектами.
Советы для успешного освоения новых инструментов
- Не пытайтесь объять необъятное. А «необъятное» — это именно про Big Data. Сфокусируйтесь на одной технологии и изучайте её шаг за шагом.
- Общайтесь с другими специалистами для обмена опытом и решения задач. Для этого есть тематические форумы, группы в соцсетях. Да и просто нетворкинг сам по себе хорош.
- После каждого пройденного модуля обучения делайте заметки о том, что вы узнали и как это можно применить на практике.
- Постоянно практикуйтесь в небольших проектах или решайте разовые задачи по аналитике данных.
Изучение ИИ, облачных вычислений, блокчейна, IoT и новых платформ по типу Snowflake или Delta Lake поможет вам освоиться в биг дате и проводить такую аналитику данных, которая поможет бизнесу решать стратегические задачи, а вам — больше зарабатывать. Направление очень прибыльное и относительно российского рынка новое, так что, освоив 5 главных решений, вы точно будете востребованы на рынке труда! 😉